수동 키워드 조사는 결국 사람의 컨디션을 타는 작업이에요.
오늘은 잘 찾다가도, 내일은 똑같은 화면만 보고 끝나죠.
그런데 트래픽은 “내가 조사할 때”가 아니라 “검색이 움직일 때” 터집니다.
그래서 필요한 게 디스커버리 엔진이에요.
키워드를 ‘찾는’ 게 아니라, 사이트 데이터와 SERP를 연결해서 키워드가 알아서 흘러들어오게 만드는 구조요.
🔥이 글은 툴 나열이 아니라, 오늘 바로 설계하고 이번 주 안에 굴릴 수 있게 만드는 흐름으로 갈게요.

🎧 글 읽기 귀찮다면 재생부터 눌러보세요.
듣고 나면 내용이 더 빨리 들어옵니다.
같은 카테고리 안의 다른 주제를 다룬 글도 읽어 보시길 추천드립니다.
👉“3P(Proof·Process·Perspective) 기획 구조” 보러 가기
빠르게 찾아보기
수동 조사가 무너지는 진짜 이유
키워드 조사는 보통 이런 패턴으로 무너져요.
처음엔 의욕적으로 엑셀을 켜고, 툴을 몇 개 열죠.
그런데 시간이 지나면 “이게 맞나?”가 오기 시작합니다.
왜냐하면 수동 조사는 정적인 리스트를 만들기 때문이에요.
검색어는 계속 바뀌는데, 내 리스트는 멈춰 있죠.
🚨결국 한 달 뒤엔 그 엑셀이 “그때의 내 감”만 담은 문서가 됩니다.
반대로 디스커버리 엔진은 출발점이 달라요.
정답 키워드를 찾는 게 아니라, 데이터가 움직일 때마다 후보가 자동 생성되게 만들거든요.
여기서부터 게임이 바뀝니다.
디스커버리 엔진이 하는 일은 딱 하나
디스커버리 엔진은 복잡해 보이지만, 본질은 단순해요.
지금 내 사이트가 먹을 수 있는 주제”를 자동으로 뽑아주는 파이프라인입니다.

핵심은 두 가지 신호를 섞는 거예요.
내 사이트 신호(GSC)와, 시장 신호(SERP).
예를 들어 이런 상황이 있죠.
어떤 쿼리는 노출이 꽤 나오는데 클릭이 안 나와요.
또 어떤 페이지는 6~9위에서 계속 맴돌아요.
💡이건 “조금만 맞추면 올라갈” 가능성이 큰 구간입니다.
GSC API를 연결해서 현재 순위 4~10위 사이 기회 키워드를 실시간 탐지하는 구조가 핵심이라고 정리된 자료가 있어요.
즉, 디스커버리 엔진은 ‘새 키워드 찾기’가 아니라 기회 구간을 포착하는 레이더에 가깝습니다.
전체 구조는 파이프라인으로 생각해야 한다
여기서 많은 분들이 실수해요.
“자동화 툴 하나로 끝내려는” 쪽으로 가거든요.
그럼 금방 막힙니다.
디스커버리 엔진은 툴이 아니라 흐름이에요.
저는 이렇게 5단으로 잡는 걸 추천해요.
💡시드 수집 → 확장 → 정리 → 군집화 → 우선순위
이걸 n8n이나 Python이 대신 돌려주는 거고요.
n8n은 레고처럼 노드를 연결하는 느낌이라 빠르게 만들기 좋고,
Python은 데이터가 커질수록 튼튼해요.
처음엔 n8n으로 시작하고, 나중에 Python으로 옮기는 것도 흔한 흐름입니다.
이제 각 단계에서 “무엇을 결정해야 하는지”만 딱 잡아볼게요.
시드 데이터는 GSC에서 뽑아야 빨라진다
시드는 아무 데서나 뽑을 수 있어요.
하지만 수익형 블로그라면 제일 빠른 건 GSC입니다.
이미 구글이 내 사이트를 어떤 쿼리로 노출시키는지 알고 있거든요.
여기서 목표는 “대박 키워드”가 아니에요.
CTR이 낮거나, 순위가 애매한데 노출이 있는 쿼리를 잡는 겁니다.
왜냐하면 이건 이미 구글이 내 페이지를 후보로 올려놨다는 뜻이거든요.
이 단계에서 필요한 결정은 하나예요.
“시드를 어떤 조건으로 뽑을 거냐”죠.
추천 조건은 이렇게 잡으면 안정적이에요.
- 노출은 있는데 CTR이 낮은 쿼리
- 평균 순위가 4~10 사이인 쿼리
- 최근 28일에 갑자기 노출이 늘어난 쿼리
이렇게 뽑으면, 다음 단계에서 확장했을 때도 엉뚱한 방향으로 새지 않습니다.
그리고 이 시드가 쌓이면, 수동조사로 돌아가기 싫어져요.
💡매번 “뭘 써야 하지?”가 아니라 “뭐부터 처리하지?”가 되거든요.
확장은 LLM이 하고 사람은 룰을 정한다
이제 시드를 롱테일로 늘려야 해요.
다만 중요한 건 “생성”이 아니라 확장 규칙이에요.
예를 들어 시드가 “무선 청소기 필터”라면,
그냥 관련 키워드 50개 뽑는 건 의미가 약해요.
대신 이렇게 룰을 걸어야 합니다.
- 고장/문제 상황 질문으로 확장
- 교체/구매/호환 같은 행동 의도로 확장
- 브랜드/모델명 결합으로 확장
- 비교 프레임으로 확장
이런 식으로요.
GPT-4o 같은 모델로 시드를 롱테일과 대화형 질문(PAA) 세트로 무한 확장하는 블록을 제안하는 자료도 있습니다.
여기서 사람은 뭘 하냐면, “우리 사이트가 먹을 의도만 남기기”를 해요.
확장 자체는 자동이지만, 확장 방향은 사람이 잡아야 비용도 덜 새고 결과도 좋아집니다.
군집화는 임베딩으로 해야 자기잠식을 막는다
키워드를 많이 뽑아두면 다음 문제가 바로 터져요.
비슷한 글을 여러 개 쓰게 됩니다.
그리고 어느 순간부터 순위가 서로 싸우기 시작하죠.
이게 키워드 자기잠식이에요.
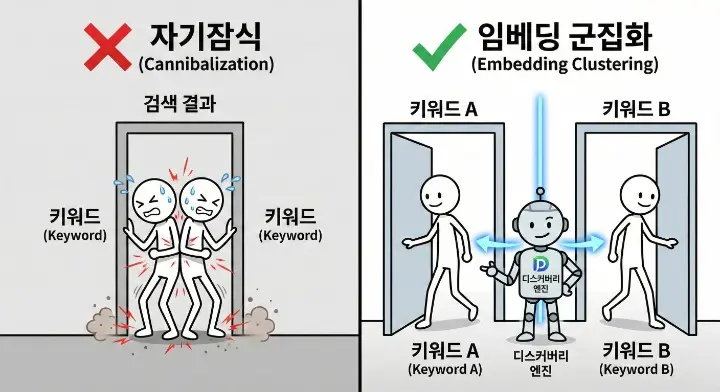
그래서 군집화가 필요합니다.
여기서 텍스트 매칭으로 묶으면 정확도가 떨어져요.
“단어는 다른데 의도는 같은” 케이스를 못 잡거든요.
💡그래서 임베딩을 씁니다.
문장을 좌표로 바꿔서, 가까운 것끼리 묶는 방식이죠.
비유로 말하면 이래요.
키워드를 ‘글자’로 보는 게 아니라 ‘의미의 거리’로 보는 겁니다.
sentence-transformers 같은 임베딩 모델과 벡터 DB를 써서 SERP 유사도 기반 클러스터링을 한다고 정리된 자료도 있습니다.
저는 여기서 한 번 더 안전장치를 거는 편이에요.
클러스터를 만들고, SERP 상위 URL을 같이 긁어서 URL 중복도를 체크합니다.
상위 결과가 비슷하면 같은 의도일 확률이 높아요.
이걸 자동으로 체크해두면, 나중에 콘텐츠가 늘어도 구조가 무너지지 않습니다.
우선순위는 ‘검색량’보다 ‘지금 이길 확률’로 잡는다
많은 분들이 여기서 다시 수동조사 습관으로 돌아가요.
검색량 높은 것부터 하려는 거죠.
그런데 디스커버리 엔진은 그 반대로 가야 성과가 빨라요.

💡우선순위 점수는 이렇게 잡는 게 현실적입니다.
- 내 사이트가 이미 노출을 받는가
- 현재 순위가 4~10에 걸려 있는가
- SERP가 정보글 위주인가, 쇼핑/브랜드 위주인가
- 내 기존 글과 겹치는가
- 지금 만들 수 있는 페이지 타입이 명확한가
의도를 수치화해서 페이지 유형(블로그, 랜딩페이지 등)에 자동 매핑하는 흐름이 핵심이라는 자료가 있습니다.
이게 왜 중요하냐면,
키워드만 뽑아놓고 “어떤 페이지로 풀지”가 안 잡히면 실행이 멈춥니다.
반대로 페이지 타입까지 정해져 있으면, 바로 제작으로 넘어가요.
디스커버리 엔진의 목적은 키워드 DB가 아니라 생산 백로그니까요.
n8n으로 굴리는 실행 흐름은 이렇게 잡는다
여기서부터는 실제로 굴러가게 만드는 파트예요.
n8n 기준으로 가장 무난한 흐름은 이렇습니다.
트리거는 스케줄러로 잡고, 결과는 시트나 Airtable로 쌓아요.
Slack을 붙이면 팀이면 더 편하고, 혼자면 알림용으로만 써도 충분합니다.
아래 표처럼 한 번에 설계하면, 이후엔 “조정만 하는 운영”으로 바뀝니다.
| 단계 | n8n에서 하는 일 | 결과물 |
|---|---|---|
| Trigger | 매일/매시간 스케줄 실행 | 실행 로그 |
| Collect | GSC API + SERP 수집(SerpAPI/Apify) | 시드/경쟁 데이터 |
| Expand | LLM으로 롱테일/질문 확장 | 확장 키워드 |
| Cluster | 임베딩 + SERP URL 유사도 체크 | 클러스터 |
| Score | 기회구간/중복/의도 기반 점수화 | 우선순위 백로그 |
이 구조로 한 번 굴리면, 다음부터는 “키워드 조사 시간”이 사라져요.
대신 “백로그 승인 시간”만 남습니다.
이건 제 개인적인 생각이지만 글쓰기 뿐만이 아니라 모든 자동화는 100퍼센트는 없다고 생각합니다.
완전 자동화는 환상이고, 승인 자동화는 사고가 납니다.
AI 검색과 추천 노출은 ‘클러스터’에서 갈린다
요즘은 검색만 보는 게 아니라, 추천과 요약 노출까지 같이 봐야 하죠.
그래서 디스커버리 엔진이 더 중요해졌습니다.
💡AI 검색/추천 쪽은 “키워드 하나”보다 주제 덩어리를 더 신뢰하는 경향이 있어요.
프로그램매틱 SEO 쪽 분석 글에서도, AI로 확장한 페이지를 무작정 늘리기보다 주제 클러스터와 내부 구조를 먼저 잡는 쪽이 노출 안정성이 높다는 식으로 정리합니다.
그래서 엔진 설계에서 군집화가 빠지면, AI 추천 흐름에서도 손해를 봐요.
또 하나.
대량 처리를 하면 비용과 한도가 바로 문제 됩니다.
키워드 확장과 군집화는 호출량이 커지기 쉬워서요.
💡OpenAI Batch API를 쓰면 비동기 처리로 비용을 최대 50% 절감할 수 있어요.
Batch API는 여러 요청을 파일로 묶어 예약 처리하는 방식이라,
실시간 호출 대신 저렴한 비용으로 대량 작업을 한 번에 처리할 수 있습니다
이건 “아껴보자” 수준이 아니라, 엔진이 멈추지 않게 만드는 안전장치에 가까워요.
자주 터지는 실패 지점과 막히는 순간
여기까지 만들고도, 실제 운영에서 많이 터지는 지점이 있어요.
이건 미리 알고 가는 게 시간 줄이는 방법입니다.
🚨가장 흔한 건 두 가지예요.
첫째, 콘텐츠가 얇아지는 문제입니다.
엔진이 키워드를 잘 뽑아도, 결과물이 얇으면 아무 의미가 없어요.
둘째, 의도 혼재입니다.
Mixed Intent 키워드를 AI가 한쪽으로 단정해버리면, 페이지 타입이 어긋납니다.
예를 들어 “OO 추천”인데 실제 SERP는 비교표+쇼핑이 강한데, 블로그 정보글로만 가버리는 거죠.
그래서 저는 승인 단계에서 딱 한 가지만 보라고 해요.
SERP 상위 5개가 어떤 페이지인지요.
이거 하나만 봐도, 엔진이 제안한 페이지 타입이 맞는지 바로 감이 옵니다.
오늘 바로 만드는 최소 버전은 이 정도면 충분하다
처음부터 완벽하게 만들 필요 없어요.
오히려 완벽주의로 시작하면, 구축만 하다 끝납니다.
최소 버전은 이렇게 잡으면 됩니다.
GSC에서 시드 뽑기 → LLM 확장 → 시트 저장 → 사람 승인
군집화와 점수화는 그다음 주에 붙여도 돼요.
중요한 건 “매일 자동으로 후보가 쌓이는 경험”을 만드는 겁니다.
그 순간부터 수동조사로 돌아가기가 싫어지거든요.
그리고 그때, 진짜로 할 일이 바뀝니다.
키워드를 찾는 사람이 아니라, 기회를 선택하는 사람이 돼요.
디스커버리 엔진은 그 전환을 만드는 장치입니다.
FAQ
Q. 디스커버리 엔진을 만들면 키워드 툴은 아예 안 써도 되나요?
완전히 끊기는 건 아니에요.
다만 “찾는 용도”가 아니라 “검증용”으로만 쓰게 됩니다.
중심은 GSC와 SERP 흐름으로 옮겨가요.
Q. n8n만으로도 군집화까지 가능할까요?
가능은 한데 데이터가 커지면 힘들어져요.
처음엔 n8n으로 흐름을 만들고, 임베딩/클러스터링은 Python이나 별도 서비스로 분리하는 방식이 안정적입니다.
Q. 자동화했는데도 결과가 엉뚱한 키워드로 새는 이유가 뭔가요?
시드 조건이 넓거나, 확장 프롬프트 룰이 느슨한 경우가 많아요.
시드를 GSC의 ‘기회 구간’으로 좁히고, 확장도 문제/구매/비교 같은 행동 의도로 제한하면 바로 잡힙니다.